Tuning Search to Claude.ai Level
Part 1 explains the mechanics (tutorial); Part 2 validates with data (experiment report)
The last eval pinned the gap: fixing the model and varying only the harness, my hand-rolled agent delivered 37% / 80% ≈ 46% of Claude.ai — and search precision alone accounted for nearly half the failing tasks. This post cashes in that "after the P0 optimization" flag.
- Part 1 · Tutorial: the 5 engineering optimizations behind Claude.ai's fast+accurate search, each with an API example and official citation.
- Part 2 · Experiment report: each treatment tested on a hand-rolled harness, with latency / token / per-task pass-fail data.
Up front: Claude.ai's search is not a magic engine (its backend is actually Brave Search — citation overlap with Brave's top results is ~86.7%). Its "fast and accurate" is 5 decomposable, replicable engineering optimizations. Here's each, with something you can copy.
1Content returns inline with results — no separate fetch
Mechanic: one web_search call returns, per result, ~500 words of query-relevant page content already attached, passage-selected index-side. One search yields the relevant text — no separate fetch, no extra model call to extract.
Example: a request with the search tool
POST /v1/messages
{
"model": "claude-opus-4-...",
"tools": [{ "type": "web_search_20250305",
"name": "web_search", "max_uses": 5 }],
"messages": [{ "role": "user", "content": "..." }]
}Shape of each returned result (note encrypted_content)
{
"type": "web_search_tool_result",
"content": [{
"type": "web_search_result",
"url": "https://en.wikipedia.org/wiki/...",
"title": "...",
// ↓ ~500 words, query-selected, goes straight into context
"encrypted_content": "EqgfCiB...(~4000-6300 bytes)",
"page_age": "..."
}]
}Contrast: Claude Code (the CLI) discards those inline snippets, keeping only title/url, and re-fetches via WebFetch (Turndown + Haiku) when needed. Same engine, two content pipelines.
Sources: Web Search Tool (official) · The Claude Code WebSearch Black Box · Inside Claude Code's Web Tools
2Server-side execution + tool/generation overlap
Mechanic: search runs inside Anthropic's infra (no client round-trips), and the model can emit multiple tool calls in one message, executed in parallel.
Example: parallel tool calls in one assistant turn
"content": [
{ "type": "tool_use", "id": "a", "name": "web_search",
"input": { "query": "..." } },
{ "type": "tool_use", "id": "b", "name": "web_search",
"input": { "query": "..." } } // two in parallel
]Can you do it? Parallel tools — yes (run tool execution with Promise.all). Server-side co-location and generation-overlap — no, that's the moat. The good news: those aren't the bulk of the speed.
Source: Parallel Tool Use (official)
3"Code filtering," not "call another model"
Mechanic: when results are many, dynamic filtering has the model write code and run it in a sandbox to filter/rank/extract, sending only the code's output into context. Deterministic, token-cheap, zero extra model round-trips.
Example: with code execution on, the model writes the filter
# Claude generates and runs inside code_execution:
results = load_search_results()
hits = [r for r in results
if "Highlands and Islands" in r["text"]
and any(y in r["text"] for y in ("2021","2016"))]
print(hits[:3]) # only these enter contextVersus "ask another LLM to read and filter": that's a full inference round-trip (100s of ms to seconds); code filtering is milliseconds. This becomes the mirror for the mistake I make below.
Source: Advanced Tool Use (programmatic tool calling)
4Prompt Caching: cache the stable prefix, up to 85% latency cut
Mechanic: cache the big, stable tools + system prefix; rounds 2+ read it. Official numbers: up to 85% latency and 90% cost reduction; a 100K-token example dropped from 11.5s to 2.4s.
Example: cache_control breakpoint on system / last tool
{
"system": [{ "type": "text", "text": "<long system prompt>",
"cache_control": { "type": "ephemeral" } }],
"tools": [ ...,
{ "name": "web_search", ...,
"cache_control": { "type": "ephemeral" } } ] // caches the tools block
}tools → system → messages, and the cached prefix must be stable. Cache only tools+system; never put per-turn-changing tool results inside the cached region, or it invalidates every turn and gets slower — there's an arXiv study on exactly this (boundary control improves TTFT 13–31%; naive full caching increases latency).
Sources: Prompt Caching (official) · Prompt Caching docs · "Don't Break the Cache" (arXiv)
5Selective retrieval after search, not bulk-fetch every time
Mechanic: the docs recommend search → selective retrieve. Simple factual queries use 1–3 searches, with max_uses bounding the count.
Example: bound the number of searches
"tools": [{ "type": "web_search_20250305",
"name": "web_search",
"max_uses": 3 }] // latency-sensitive: cap at 3Source: Web Search Tool · max_uses (official)
Controlled variable: model fixed (same upstream); only the retrieval/fetch/context pipeline changes.
Dataset: 30 GAIA+FRAMES tasks the naked model fails, run in full.
Judge:
contains — whether the model's FINAL ANSWER contains the gold answer (case-insensitive).Baselines: naked model 0 / 30, original harness (B) 11 / 30 (37%), Claude.ai (C) 24 / 30 (80%).
Grade caveat: the upstream (luckyapi) is not vanilla Anthropic and temperature 0 doesn't fully reproduce, so a single run is a point estimate, not a verdict (this is also why frames_241 below is flaky).
The old architecture
The original harness was the most naive "search → fetch → char-truncate" three-stage pipeline, losing information at every layer:
- Retrieval: Serper-primary, snippets only — no body text, so a separate page fetch was forced.
- Fetch: one
web_searchauto-fetched the top 3 pages, and bare fetch doesn't render JS, so anti-bot often blocked it. - Ingestion: fetched text entered context by positional truncation
slice(0, 6000)— query-blind, so any answer past char 6000 was silently dropped (a hidden bug). - Context: Haiku compressed history only above 30k tokens (also query-blind), rewriting history every round and shattering the cacheable prefix.
- Loop: capped at 8 rounds.
Three fatal points: can't get body text, fragile fetch, answers positionally truncated; multi-hop tasks rarely survived to convergence.
The current architecture
Following the 5 optimizations dissected in Part 1, every layer was reshaped into "retrieval-style, zero extra generation, cacheable":
| layer | before | after |
|---|---|---|
| retrieval | Serper, snippets only | Brave-primary + extra_snippets (~500 words inline); 9-level fallback chain |
| fetch | top-3 every search | inline-first: don't fetch if snippet is rich; else selectively fetch top-1 |
| extraction | slice(6000) positional cut | Exa /contents highlights (embedding selection, verbatim, no LLM round-trip) |
| context | rewrite history each round | append-only + cache_control on system/tools |
| loop | 8 rounds | 16 rounds + multi-hop planning prompt + network retry |
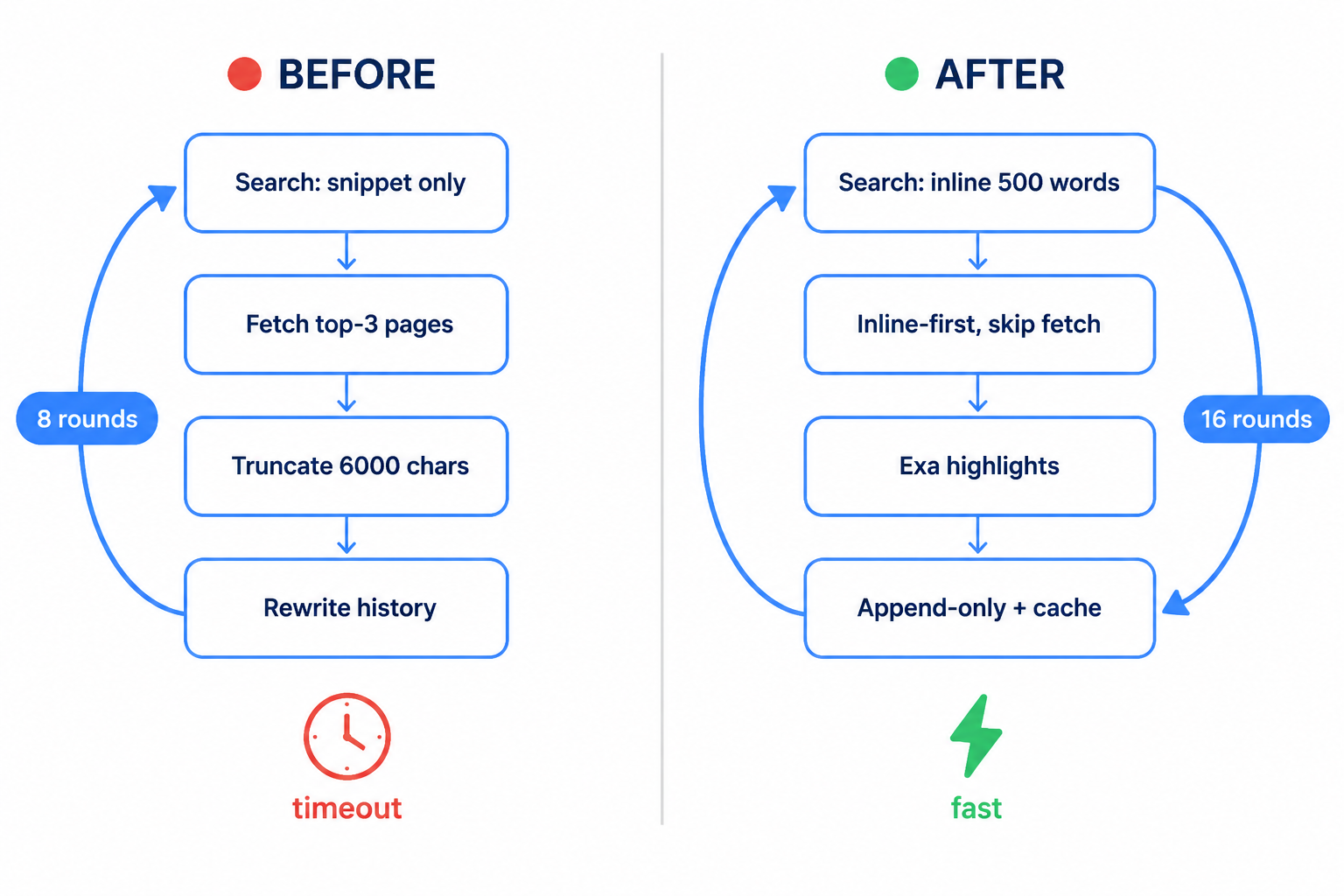
What changed
Condensed to the four behavior-changing moves (knob-tuning omitted):
- Inline-first (biggest speedup): let relevant body text come back with the search results, skip the fetch whenever possible — cutting the default "3 fetches + 3 extraction calls" per search to 0 in the common case.
- Extract by retrieval, not generation: hand "read the right passage" to Exa highlights (semantic selection) instead of calling Haiku per fetched page.
- Cache the stable prefix + append-only history: cache system+tools, append messages only, drop the rewrite-history-each-round hack — many-round iteration no longer recomputes the full context every turn.
- Fix the truncation bug: query-aware extraction replaces
slice(6000), killing the silent "answer past char 6000 dropped" failure.
contents param differs): summary:{query} runs a generative LLM on Exa's side = 3284ms; highlights:{query} is embedding selection returning verbatim text = 613ms (5.4× faster). Lesson: extraction wants "retrieval-style verbatim excerpts," not yet another model generating a summary — which is exactly what Claude.ai's inline snippet is. Exa Search/Contents API Results
With every change stacked (temperature 0, 16 rounds), the full 30 tasks run once against the baselines:
| harness (model held fixed) | 30-task pass | position |
|---|---|---|
| naked model (no tools) | 0 / 30 | floor |
| original hand-rolled harness (B) | 11 / 30 · 37% | start |
| after this rewrite (v3) | 20 / 30 · 67% | +30 pts |
| Claude.ai (C) | 24 / 30 · 80% | ceiling |
37% → 67% closes the gap to Claude.ai from 43 points to 13 — about two-thirds of it.
More important is latency — the old architecture's fatal flaw was "accurate but timed out." Here's each group's time / rounds / retrieval behavior:
| group | tasks | avg time | median time | avg rounds | avg searches | avg fetches | inline-only |
|---|---|---|---|---|---|---|---|
| PASS | 20 | 54s | 35s | 4.4 | 2.2 | 2.4 | 89% |
| FAIL | 10 | 93s | 40s | 8.0 | 3.4 | 3.9 | 65% |
PASS tasks hit the answer in a couple of searches (median 35s, 2.2 searches) — accurate and cheap; the full 30 average 67s/task. FAIL tasks instead searched more and ran longer and still failed (avg 3.4 searches / 8 rounds) — the blocker isn't "couldn't find it."
Narrowing to the 8 tasks the first experiment (original B harness, 8-round cap) actually solved (v3 PASSes all 8 too), a pure timing comparison:
| task | first run (B) | now (v3) | time change |
|---|---|---|---|
| gaia_016 | 32s | 7s | 4.5× faster |
| gaia_150 | 37s | 22s | faster |
| gaia_096 | 37s | 35s | ~same |
| gaia_052 | 56s | 57s | ~same |
| gaia_136 | 16s | 25s | a bit slower |
| gaia_158 | 16s | 33s | a bit slower |
| gaia_059 | 12s | 31s | a bit slower |
| gaia_153 | 41s | 79s | slower |
| 8-task total (all PASS) | 31s avg · 34.5s median | 36s avg · 32s median | same ballpark |
3 faster, 5 a bit slower; mean 31s → 36s, median 34.5s → 32s — the same ballpark (the mean is pulled up by gaia_153 alone). Takeaway: the correctness the rewrite gained on hard tasks didn't slow down the tasks that were already solvable.
Where the improvement comes from
An aggregate number can lie — 67% might be "got lucky." Break down the round-by-round logs and each change leaves a quantifiable fingerprint. First, how a single search actually flows now:
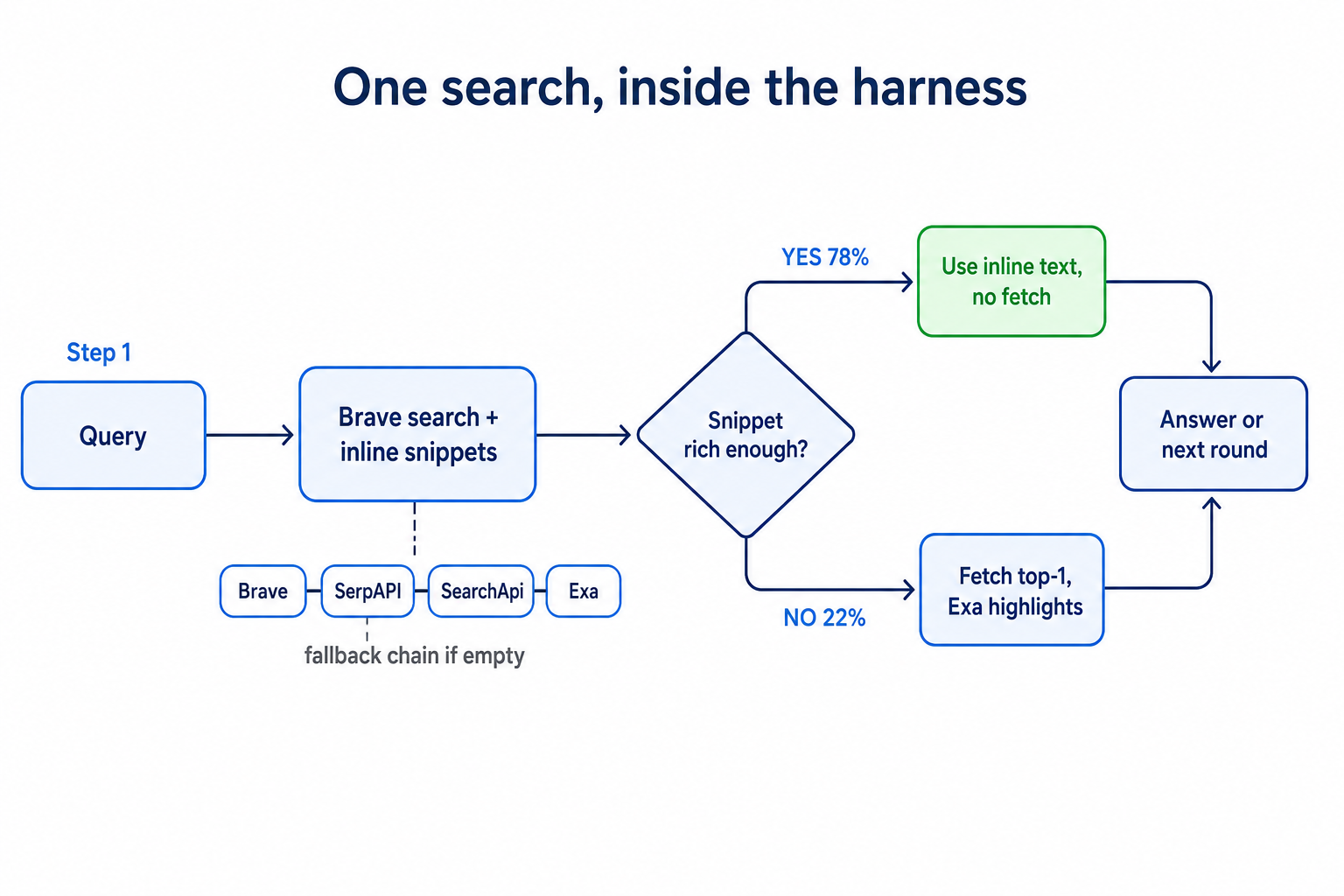
Each optimization leaves a fingerprint in the logs:
- Inline-first → speed: 61 of 78 searches (78%) fetched nothing (89% on PASS tasks) — the main reason latency dropped from "timeout" back to tens of seconds.
- Fallback chain → coverage: 67 Brave-only, 11 fell to a fallback, every one recovered to ≥3 results (zero thin sets); one went 4 levels deep (Brave→SerpAPI→SearchApi→Exa), Exa rescued 9 results and bought gaia_008 a PASS.
- highlights → fast and accurate: all 87 fetches resolved at Exa
/contentswith zero LLM round-trip, verbatim. (The robust fetch chain Jina/Firecrawl never fired: dormant insurance, no robustness evidence this run.) - Caching → sustaining many rounds: late-round uncached input drops to single-digit tokens (gaia_001 ran 11 rounds; the back half ~7–44 tokens each) — many rounds are no longer compute-expensive, the foundation for finishing instead of timing out.
The remaining 10 failures are mostly no longer in the search/fetch pipeline; they split into three classes, only one a retrieval-precision problem: ① judgment wall (gaia_110 / 014 / 128 ran the full 15 rounds, read the right text but picked the wrong entity); ② retrieval-precision wall (only gaia_029: a niche fact not in the index — 13 reformulations, 10 forced fetches, still unlocked); ③ trigger discipline (frames_543 / 647 answered after one search, frames_562 did zero — speaking before searching enough).
Conclusion and transferable principles
This round moved the bottleneck from "infrastructure" to "judgment": search accurately, fetch reliably, cheap rounds — all validated with data; what's left on the two unsolved tasks is picking the right entity in multi-hop reasoning — the next mountain, not the search pipeline. Five transferable principles:
- Inline content first: if a retrieval API returns query-relevant content directly (Exa highlights / Tavily), don't "search → fetch → call a model to extract."
- Extract via retrieval, not generation: semantic highlights (embedding selection) is an order of magnitude faster than "ask a model to summarize" (measured 613ms vs 3284ms) and verbatim.
- Cache the stable prefix, append-only history: cache system+tools, don't rewrite history each round — the precondition for affording many rounds (measured: late-round input tokens drop to single digits).
- Positional truncation is an invisible bug: slicing body text by character silently drops answers; keep by query relevance.
- Respect the moat: server-side co-location and tool/generation overlap can't be replicated — but they aren't the bulk of the speed. Inline content, caching, and code filtering are, and all three you can do.