开源 CiteScope:跟 Topify $99/月做同样的事,多做了一刀
客户案例驱动 + span attribution 差异化 + 一个 solo dev 在「商业化 vs 开源」之间的 Open Core 取舍
2026 年中,客户找供应商的方式已经悄悄变了。我做的一个 B2B 出口客户(化名 X),目前在 ChatGPT / Perplexity / Gemini 上的 AI 覆盖率是 0%。客户老板想知道两件事:怎么进 AI 短名单?竞品的 AI 弹药库在哪?市面上的 GEO 监测工具我看了一圈,Topify 99-199 美元/月、Profound 499+ 美元/月、Peec.ai 80-120 欧/月,做的事都差不多 —— 但有一刀谁都没切。所以花两周自己造了一个开源平替 CiteScope,今天发布。
AI 搜索流量正在分走 Google 的购买意图
如果你在 2026 年还在做品牌增长,八成已经发现这个不太舒服的现象:有相当一部分购买意图的流量正在从 Google 流向 AI 对话窗口。
当客户问 ChatGPT 「2026 年某品类的最佳 B2B 供应商有哪些」或问 Perplexity 「北美某行业的服务商找谁」,他们拿到的是一段 200 字的回答,点名 3-5 家供应商,带可点击的 citation 链接。他们不会再去翻十条蓝色链接。他们直接从 AI 的短名单里挑。
如果你的品牌不在这份短名单上,你就是隐形的 —— 哪怕 Google 上同样的关键词你排第一。
这就是 GEO(Generative Engine Optimization,生成式引擎优化),或者 AEO(Answer Engine Optimization,应答引擎优化),2026 年中开始更常用的叫法。一个意思:优化 AI 搜索的可见度,而不只是 Google。
这个赛道很热。Topify、Profound、Peec.ai、Otterly、AthenaHQ —— 全部在过去 18 个月里冒出来,统一收 80-500 美元/月。但它们卖的本质上是同一件事:把你的探针问题打到 AI 引擎上,记录回答和 citation,画几张图。
客户的真实需求:0% AI 覆盖率怎么破
我的 GEO 业务起源是给一个真实客户做诊断。客户化名 X,主营 B2B 出口业务(OEM/ODM 品类),目标市场欧美。背景:
- 有自己的工厂(实体生产能力),有审计认证(LRQA / Intertek 体系内)
- 过去主要靠展会 + 阿里国际站获客
- 2026 年中老板意识到大客户买家越来越多从 ChatGPT / Perplexity / Gemini 起手做供应商初筛
- 初步盘点:客户品牌在英文 AI 搜索里 0% 覆盖率。竞品(竞品 A 29%、竞品 B 34%、竞品 C 24%)已经被 AI 推荐
老板的诉求是三个问题:
- 我的品牌有没有被 AI 提到?跨引擎、跨时间窗的提及率
- AI 提及行业问题时引用了哪些站?这些就是我要去铺内容的「弹药库」
- 竞品的 AI 资产到底是什么?AI 提到某个竞品时引用了哪些 URL,反推竞品的 GEO 内容投放
第一个问题简单 —— 跑探针、看 mention 率,每家商业 GEO 工具都做。第二个问题中等 —— 域名聚合的 Top Domains 报表,主流商业工具也都做了。第三个问题是关键:商业工具大多停留在「列出竞品被引用的 URL 总数」,但没法精确说「AI 提到这家竞品的那段话里,是哪条 URL 在背书」。这才是真正的反向归因。
市场上的工具我看了一圈
正式动手前我把英文圈主流 GEO 监测 SaaS 都注册过 trial 跑了一遍。粗略归纳:
| 工具 | 定价 | AI 引擎覆盖 | 差异化点 | 缺什么 |
|---|---|---|---|---|
| Topify | 99-199 美元/月 | 7+,唯一覆盖豆包/DeepSeek/Qwen | 中文生态覆盖最全 + Source Analysis | Basic 档 100 prompt 上限对 agency 偏紧 |
| Profound | 499+ 美元/月(quote) | 10+(无豆包) | 企业 polish + 集成 HubSpot/Salesforce | 贵;中文引擎覆盖弱 |
| Peec.ai | 80-120 欧/月 + 附加 | 5(DeepSeek 是 80 欧附加) | 欧洲精瘦定价 | 引擎覆盖最窄 |
| Otterly | ~50 美元/月 | 5 | 小品牌 / freelancer 友好 | 数据深度浅 |
| AthenaHQ | 企业报价 | 5+ | agency 多客户管理 | 透明度低 + 无中文 |
共通点:都是 SaaS、都不公开数据处理细节、都没做 span attribution、都不让你自定义 AI 引擎 adapter。差异化大多是工作流打磨 + 集成丰富度 + AI 引擎覆盖数。底层数据本身不是壁垒 —— 同样的探针 prompt 打给同一个 OpenAI Responses API 拿回的就是同样的 citation。商业 SaaS 卖的是「省下你自部署的两天时间」这个差价。
整个赛道在卖一个 20 美元/月的服务,定价 200 美元/月。客观看,对没有工程能力的中小品牌方这个差价合理。但对有工程能力 + 想自定义 + 在乎数据自主的团队,存在巨大套利空间。
我决定自己造的三个理由
1. 数据自主:探针 prompt 本身就是商业策略
客户的探针 prompt 看似只是一些通用行业问题,但精心设计的 prompt 集合(哪个品类、哪些竞品名、哪些用途场景)实际上暴露了客户的市场策略。这些数据落在第三方 SaaS 数据库里 = 你的策略对厂商透明。对 X 这种正在制定 GEO 突围方案的客户,把 prompt 集合上传给一家美国 SaaS 厂商(即便是声誉好的)也是要内部审批的合规事项。自部署 SQLite 完全消除这个摩擦。
2. 差异化:我要做 span attribution
这是真正的 differentiating feature。商业工具最多告诉你:
「上周你这个品类的 AI 回答里 Reddit 被引用了 78%。」
我要的是多一句:
「Reddit 被引用 78%。其中 23% 精确地支撑了提到你品牌的句子 —— 对比 55% 支撑的是无关竞品提及或行业通用论述。」
这两个数据驱动的动作完全不同。第一个版本你只能说「Reddit 是高频引用源」—— 没用,所有竞品都知道。第二个版本你能区分「Reddit 在我品类是泛引用」vs「Reddit 是我品牌的真实背书源」vs「Reddit 引用了我品类里所有人除了我」。最后一种情况意味着真实的内容缺口(gap analysis)。
3. 国内 AI 引擎覆盖:豆包 / Kimi / DeepSeek
如果客户只做欧美出口,国际 AI 引擎够用。但 X 也希望覆盖国内询盘场景(部分国内大客户问豆包要供应商推荐),同时下一阶段想扩展到给国内品牌做 GEO 服务。这意味着豆包 / Kimi / DeepSeek 必须能接入。市场上唯一同时覆盖国际 + 中文引擎的 Topify 跟我聊过 trial,但他们的 Doubao 走 cookie 逆向,账户级 token 失效率高。我希望走官方 API —— 2026 Q1 上线的火山方舟 Ark Responses API + web_search 内置工具就完美满足。
CiteScope 是什么
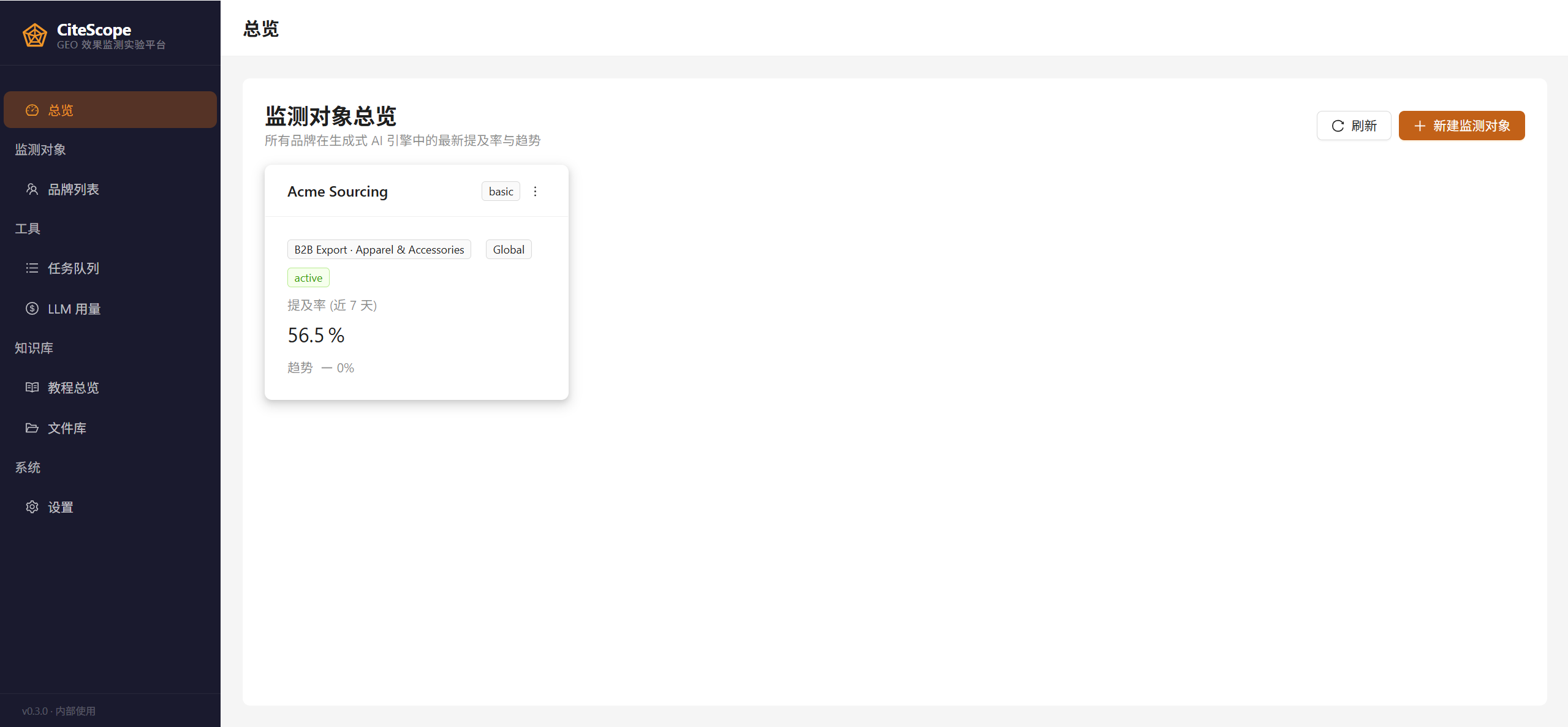
UI 长这样 —— 主页总览显示所有客户的 7 天提及率:
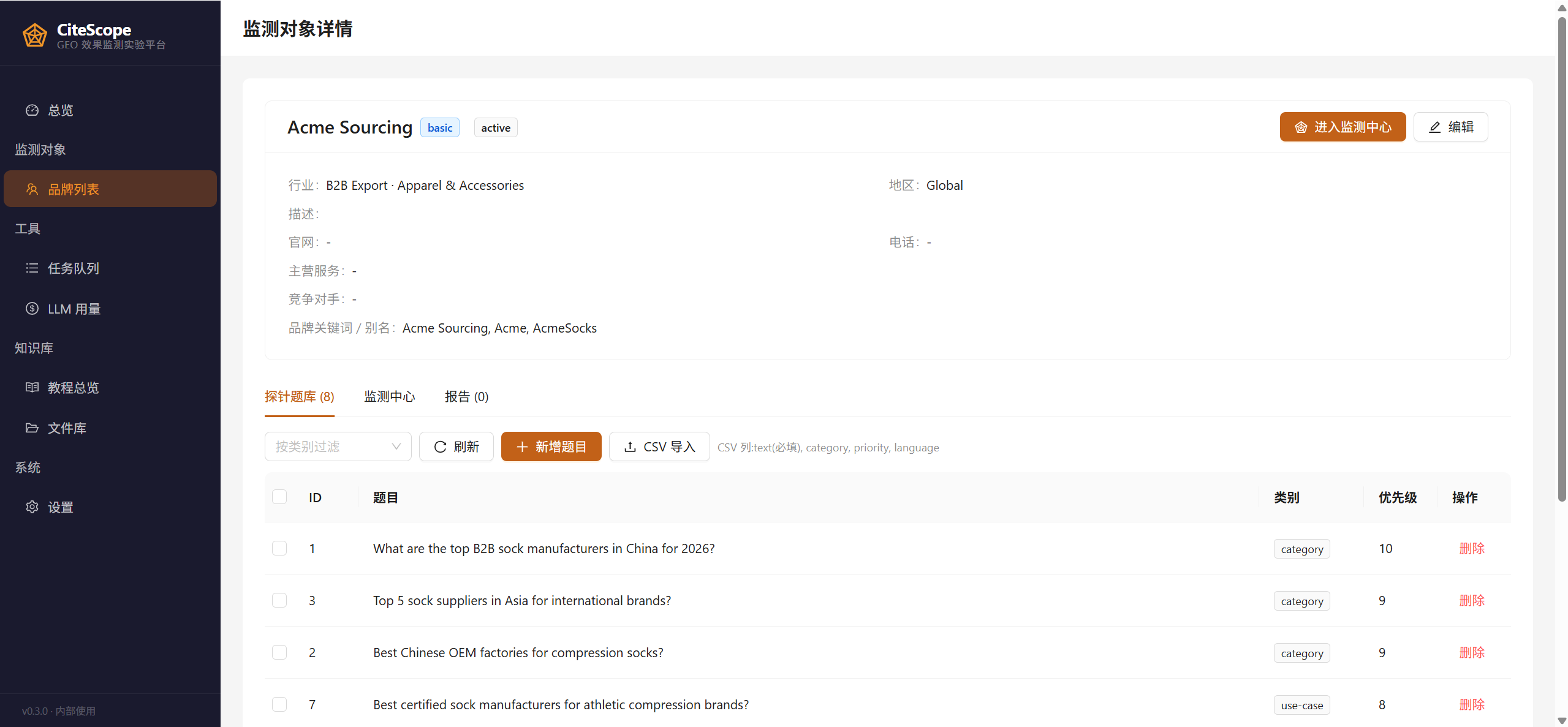
每个监测对象有独立的「探针题库」,CSV 可批量导入,问题按 category / competitor / use-case 分类管理:
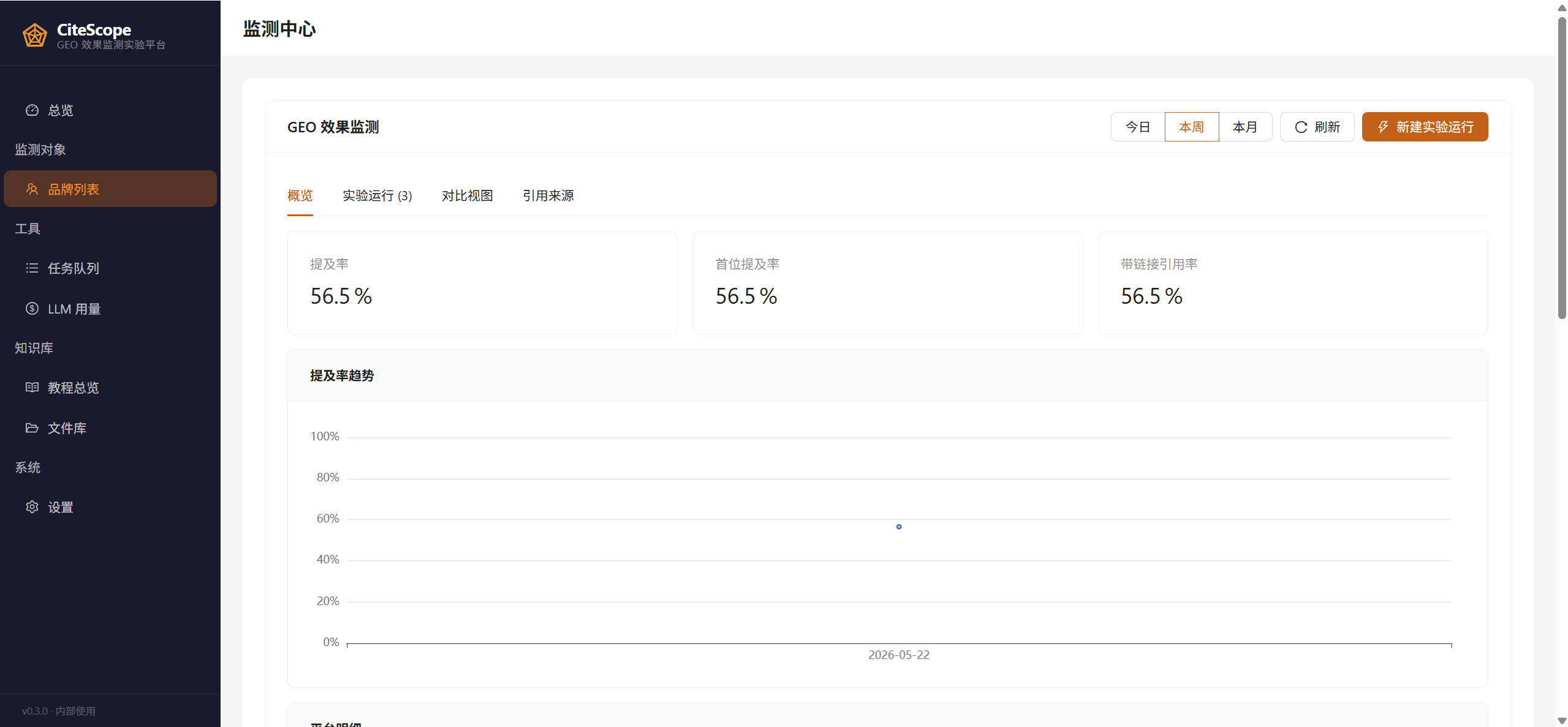
核心工作单位是 Run —— 一次 Run = 一组探针 × 多家 AI 引擎 × 一个时间点。监测中心的「概览」Tab 给出该客户的 KPI 仪表板:
架构 30 秒版:
React + Vite + Antd 5
│ HTTP/REST
▼
FastAPI + uvicorn + SQLAlchemy + APScheduler
│
├──→ AI 适配器 ×6 (ChatGPT/Perplexity/Gemini/豆包/Kimi/DeepSeek)
├──→ SQLite (WAL 模式)
└──→ 后台 citation resolver job (每 5min 一批 Gemini wrapper)
单进程 + 单 DB 文件,起步不需要 Redis / Celery / Postgres。1 vCPU / 1 GB 内存够用。一行 docker compose up -d 起服务,localhost:3000 打开。
核心差异化:span attribution 是什么
这是 CiteScope 跟所有商业工具最大的区别,值得花一段讲。
AI 回答里通常有 [citation:N] 标记(或者 OpenAI 的 url_citation annotation,Gemini 的 groundingMetadata,Volcengine Ark 的 annotation)。每条 citation 都有 start_index 和 end_index,指向它在 AI 回答正文中支撑哪段话。
商业工具拿这些 citation 时只用了一半信息:URL + title。它们丢掉了 span 信息。所以最多告诉你「这个域名被引用了 N 次」。
CiteScope 多做了一步:把 [citation:N] 标记位置和品牌词位置都计算出来,按句子切分 AI 回答,判断 citation 是否落在跟品牌提及同一句话里。如果是,这条 citation 就是真实支撑你品牌的;如果不是,它只是泛引用。
算法是 90 行 Python(backend/app/services/citation_analysis/span_attribution.py)。核心逻辑:
def compute_supports_brand_mention(
raw_answer: str,
brand_keywords: list[str],
cite_indices: list[int],
) -> dict[int, bool]:
# 1) 找所有品牌关键词出现的 char 区间 (大小写不敏感)
brand_spans = find_keyword_spans(raw_answer, brand_keywords)
# 2) 找所有 [citation:N] marker 的位置, 按 N 分组
markers_by_n = find_citation_markers(raw_answer)
# 3) 按句子切分 (中英文混排标点),
# 每个句子查: 既包含某个 brand_span 又包含某个 marker → 该 N = True
supported = set()
for s, e, _ in iter_sentence_spans(raw_answer):
has_brand = any(span_overlaps(bs, be, s, e) for bs, be in brand_spans)
if not has_brand:
continue
for n, ms in markers_by_n.items():
if any(span_overlaps(ms_s, ms_e, s, e) for ms_s, ms_e in ms):
supported.add(n)
return {n: (n in supported) for n in cite_indices}
难点不在算法,在三个细节:(1) 中英文混排的分句(中文句号后通常无空格,英文句号紧贴中文字符也要切);(2) 各家 AI 引擎返回的 citation 标记归一化;(3) 插标记到原始正文(OpenAI / Ark 返回的是 span index,需要按 end_index 倒序插 [citation:N] 让后续算法能跑)。
三个细节我各踩过一次坑。OpenAI 的 chat completions + search-preview 不返回 span(只有 annotations 数组),所以 ChatGPT adapter 暂时只能「全文级」归因;Gemini 的 grounding_supports 有 segment.start_index/end_index,需要手动重组;Ark 的 url_citation 跟 OpenAI Responses 几乎对齐但字段名是 input_tokens/output_tokens。整套对齐工作两周做完。
为什么商业工具不做这个?我猜两个原因:(1) 计算成本不低,且营销卖点不直观 —— 「Reddit 78% 引用」比「Reddit 30% 背书你品牌」看起来更醒目;(2) 一旦做了会暴露大多数「citation 追踪」实际多浅。这是 committing-to-shipping 的问题,不是算法问题。
真实数据效果:客户 X 跑出来的 Top Domains
客户 X 跑了三个 Run(baseline + 改 llms.txt 后 + 加 FAQ schema 后),3 周时间,约 700 条 citation。Top Domains 报表给出来的「AI 弹药库」是:
| 域名 | 被引次数 | 跨平台 | 解读 |
|---|---|---|---|
made-in-china.com | 40 | 3 平台 | B2B sourcing 顶流,AI 视为权威 |
alibaba.com | 32 | 2 平台 | 同上,但 ChatGPT 偏好略低 |
competitor-a.com | 31 | 2 平台 | 竞品 A 自家官网 —— 强 SEO 信号 |
competitor-b.com | 20 | 3 平台 | 竞品 B 自家官网 |
competitor-c.com | 19 | 3 平台 | 竞品 C 自家官网 |
industry-listicle-a.com | 19 | 3 平台 | 行业 top 10 榜单文章 |
jingsourcing.com | 12 | 3 平台 | 采购代理博客 |
industry-listicle-b.com | 11 | 1 平台(Gemini) | Gemini 解析出的「隐藏」权威 |
这份清单可直接转化为三类内容投放动作:
- marketplace listing 优化:在 made-in-china.com / alibaba.com 上把客户的 listing 做完整(认证图、产品规格、视频)—— 这是顶流权威
- cluster journalism 进入:industry-listicle-a.com / industry-listicle-b.com 这种「top 10 行业供应商」博客,去找作者邮件 pitch 把客户加进去(带认证 + 案例)
- 竞品 reverse engineering:去 competitor-a.com / competitor-b.com / competitor-c.com 看它们的页面 schema / FAQ 块 / 客户案例怎么写的,对照差距
更重要的是 Run 对比视图能验证 GEO 干预动作的因果效果。下图是客户的三次 Run 对比 —— 矩阵显示提及率从 baseline 0% → 改 llms.txt 后 30.4% → 加 FAQ schema 后 56.5%,雷达图同时显示三个平台的偏好差异:
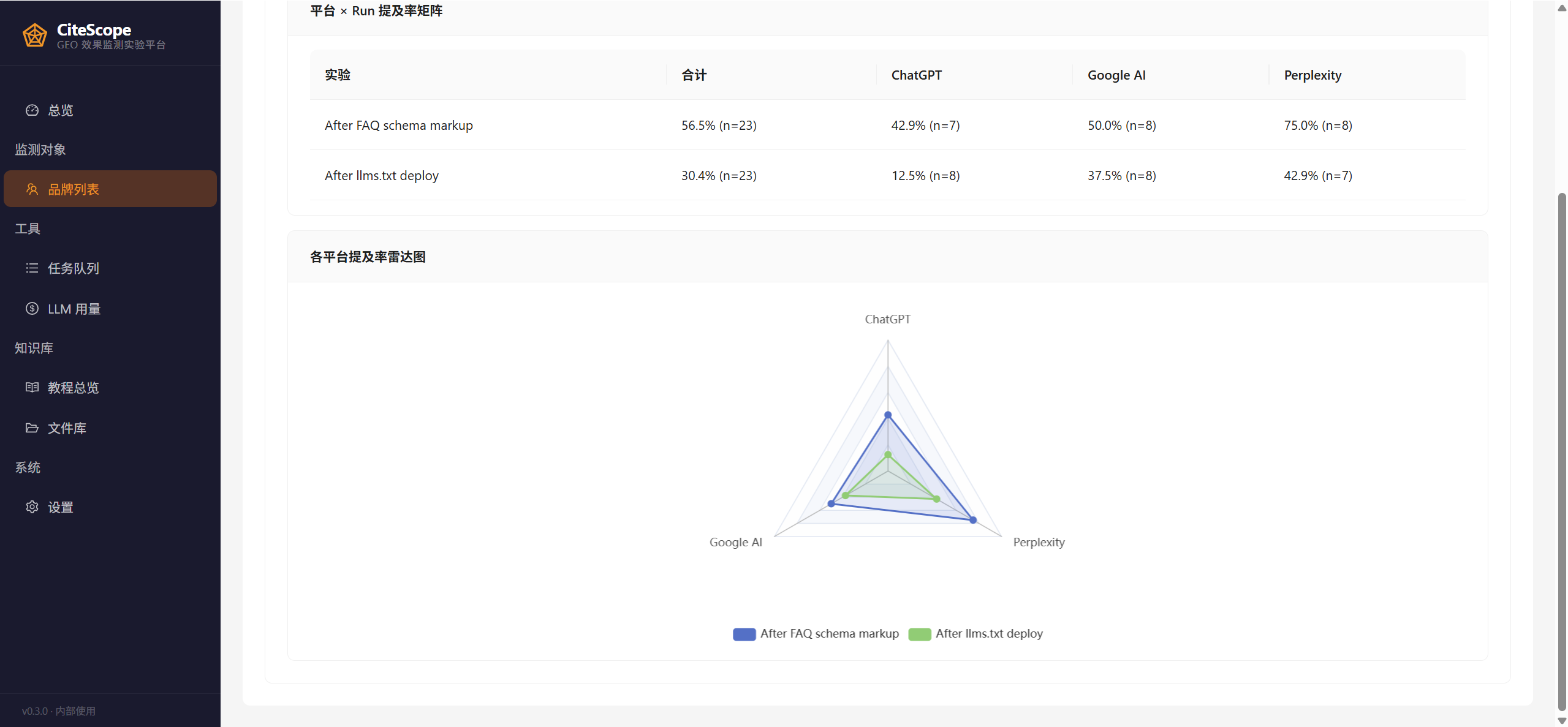
没有 Run 对比就没法做这种因果归因。CiteScope 把每轮监测当作一个版本化的 Run(带名字 + note),跨 Run 对比是它跟 Topify「每周自动跑一次然后画线图」的本质区别 —— 后者只能看趋势,前者能验证假设。
怎么自己跑
一行命令:
git clone https://github.com/piglet12138/CiteScope.git cd CiteScope cp backend/.env.example backend/.env # 打开 backend/.env 填三把 key: # OPENAI_OFFICIAL_API_KEY=sk-... # PERPLEXITY_API_KEY=... # GOOGLE_AI_API_KEY=... docker compose up -d # 浏览器打开 http://localhost:3000
填 key 的页面长这样 —— 默认进入「AI 搜索 / 监测平台」Tab,每个平台一张卡片,配套申请链接 + 测试连通按钮:
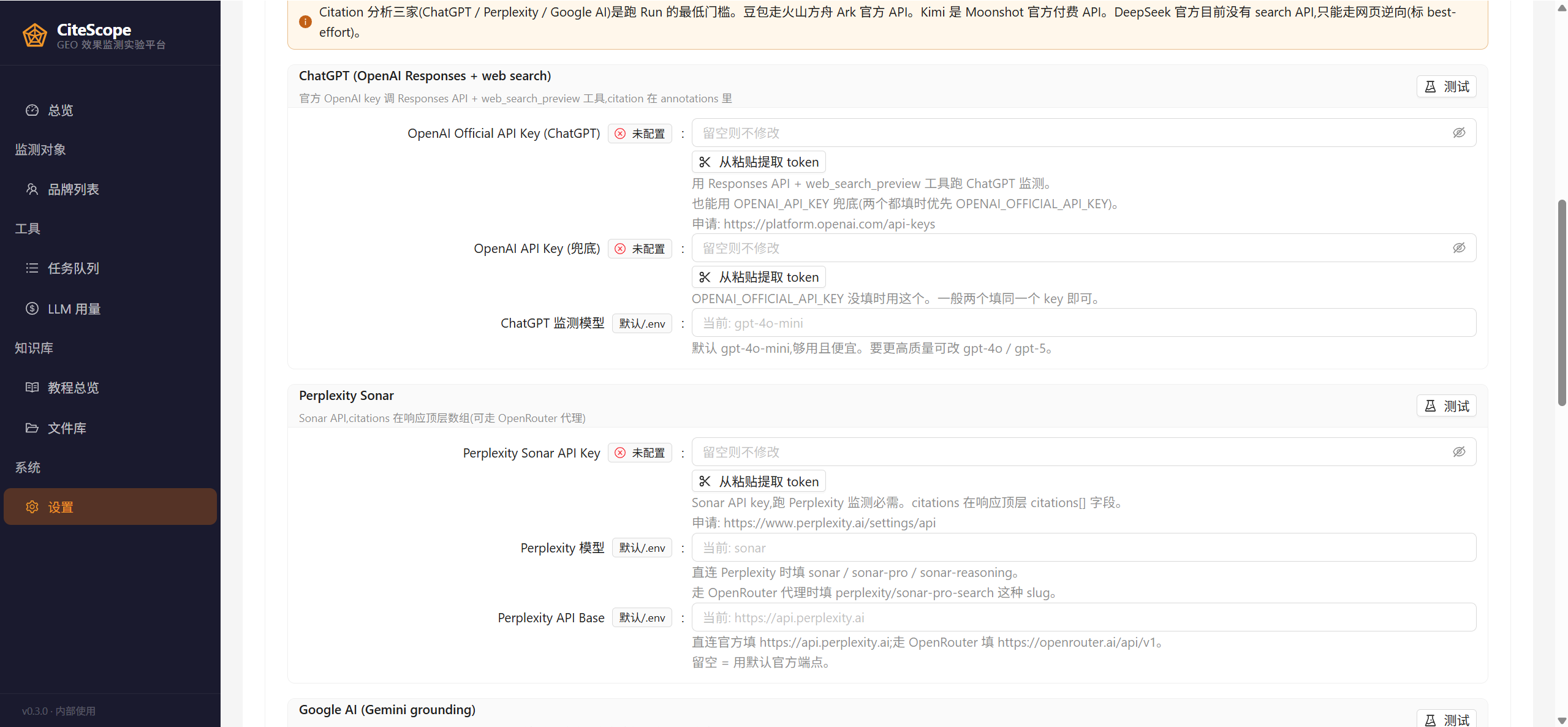
API key 申请:
- OpenAI Official:platform.openai.com/api-keys(跑 ChatGPT web search)
- Perplexity Sonar:perplexity.ai/settings/api(或走 OpenRouter,PERPLEXITY_API_BASE 改成
https://openrouter.ai/api/v1) - Google AI Studio:aistudio.google.com/apikey
- 可选 火山方舟 Ark:volcengine.com/product/ark(豆包)
预算估算:100 prompt × 3 平台 × 每周 1 次的典型频率,API 月成本 5-15 美元。Topify 卖你同样的数据 99 美元/月。
setup 完之后到 localhost:3000 → 品牌列表 → 新建客户 → 录入探针问题 → 监测中心 → 新建实验运行。5 分钟跑完,引用来源 Tab 就有 Top Domains + Competitor Assets 报表。
完整的使用手册站内嵌入 —— 不要把用户赶到 GitHub wiki,直接 /guides 路由就能读。8 个模块独立 guide,markdown 渲染:
为什么开源不直接卖 SaaS
这是这两周问自己最多的问题。把客户这个真实案例 + 差异化 feature + 已经做出来的产品打包成 SaaS 卖 49 美元/月,理论上可行。最后还是选了开源。三个理由。
1. Solo dev 没有 12 个月全职 runway
我同时在做客户的 GEO 业务、Lucky GitHub agent、claude-ai-harness、claude-zh CC fork 等几个项目。把 CiteScope 商业化意味着 6-12 个月全职做 GTM(落地页 / SEO / 内容营销 / 客户支持 / 国际收款合规),跟 VC 加持的 Topify / Profound 正面对抗。solo + 国内主体 + 卖国际 B2B SaaS,胜率太低。
2. Open Core 已经是被验证的剧本
PostHog(analytics)/ Plausible / Cal.com / Supabase / n8n 全部是 OSS core + 后期叠 hosted SaaS,起步 1-2 人,2-3 年内做到 100K+ ARR。模式是相同的:
- 前 6 个月专注开源积累 stars / 社区反馈 / 早期 power users
- 看到重复出现的「我想用但不会自部署」的需求
- 启动 hosted version,卖给那部分用户(卖的是托管 + 多租户 + 优先支持,不是 core feature)
这条路径对 capital 效率最高 —— 前 6 个月几乎 0 边际成本,时间投入主要在维护 + 答 issue + 写博客(每周 5-10 小时),跟我手上其他项目并行。
3. 客户案例只有开源才能引用
SaaS 不能把客户的探针 prompt / citation 拿出来当公开 case study(违反客户合同)。开源工具可以:因为 客户自己 self-host,数据完全在他自己 SQLite 里,展示的是「用我的 OSS 跑出来的数据」,不是「我帮他跑然后偷出来」。这种 case study 的可信度比 100 张产品截图都高。
路线图
具体的 6 个月路径:
- Week 1-2(现在):发文 + 提交 Show HN / Reddit / 即刻 / 知乎,收第一批 stars
- Month 1:收信号 —— GitHub stars / issues / 谁 fork、看后台有没有人开「feat: hosted version please」issue
- Month 2-3:补 v0.2 features(Postgres / 多 AI 适配器 / Slack alerting)
- Month 4:决策点 —— 如果 500+ stars + 5+ 主动询问 hosted,启动 hosted 版(
citescope.cloud) - Month 5-6(如果启 hosted):multi-tenant + Stripe + 定价 19/49/199 美元月档位(全部低于 Topify 99 美元起步)。客户案例上首页
反向情况 —— 什么时候应该跳过开源直接卖 SaaS:有 12 个月 runway 全职做 / 已经有 5+ 客户排队签 / 欧美注册主体能合规收款。目前都不成立,所以路径已经定了。
我希望听到的反馈
- Bug 报告,任何类型 —— adapter 输出和 vendor 真实响应不匹配、span attribution 处理某种 Unicode 出错、运维问题
- 新 adapter 贡献,我目前没覆盖的引擎 —— Bing Copilot / Claude.ai / You.com / Brave Search 都在心愿单上。Adapter 模板很简单,复制
chatgpt.py改 60 行就能上一个新引擎 - 使用场景故事 —— 你想用这份数据做什么,商业工具不让你做的?告诉我,我优先做能解锁那些工作流的功能
GitHub Issue / Discussion 都开着。中英文都行。
最后一句
GEO 在 2027 年会变成基础线。每个在乎可发现性的品牌都会去测它。问题是测的方式 —— 是订一个 99 美元/月的 Topify dashboard,还是用自家 0 美元/月的 SQLite 文件 + 保留二次开发的自由度。
我押第二种世界。如果你也认同,给我们点个 star,跑一个 Run 试试,告诉我缺什么。
https://sg.yaoyuheng2001.me/posts/open-source-citescope/。
商业用途请通过博客联系作者授权。