Open-Sourcing CiteScope: Same Thing Topify Does for $99/Month, Plus One Move They Skipped
Customer-case-driven + span attribution as the differentiator + a solo dev's Open Core calculus between SaaS and OSS
By mid-2026, how customers find suppliers has quietly shifted. The B2B export customer I work with (pseudonymized as X) currently sits at 0% AI visibility on ChatGPT / Perplexity / Gemini. The CEO wants to know two things: how do we get into the AI shortlist, and where are the competitors' AI munitions stockpiled? I surveyed the GEO monitoring tools on the market — Topify at $99-199/mo, Profound at $499+/mo, Peec.ai at €80-120/mo — and they all do roughly the same thing. But there's one move none of them makes. So I spent two weeks building an open-source alternative, CiteScope, which launches today.
AI search traffic is taking purchase intent away from Google
If you're still running brand growth in 2026, you've probably noticed an uncomfortable pattern: a meaningful slice of high-purchase-intent traffic is migrating from Google to AI chat windows.
When a customer asks ChatGPT "who are the best B2B suppliers in category X for 2026" or asks Perplexity "which service providers should I look at for industry Y in North America," what they get back is a 200-word answer naming 3-5 vendors with clickable citation links. They don't scroll through ten blue links anymore. They pick directly from the AI's shortlist.
If your brand isn't on that shortlist, you're invisible — even if you rank #1 on Google for the same keyword.
This is GEO (Generative Engine Optimization), or AEO (Answer Engine Optimization), the term that started gaining wider use around mid-2026. Same meaning: optimize for visibility in AI search, not just Google.
The space is hot. Topify, Profound, Peec.ai, Otterly, AthenaHQ — all surfaced in the past 18 months, all charging $80-500/mo. But they're fundamentally selling the same thing: fire your probe questions at the AI engines, record the answers and citations, draw a few charts.
The customer's real need: how to climb out of 0% AI visibility
My GEO practice started with a real customer diagnosis. Pseudonym X, mainly B2B export business (OEM/ODM categories), target markets Europe and the US. Background:
- Owns its own factory (real production capacity), holds audit certifications (within the LRQA / Intertek systems)
- Historically acquired customers via trade shows + Alibaba International Station
- Mid-2026 the CEO realized large buyers increasingly start supplier shortlisting on ChatGPT / Perplexity / Gemini
- Initial audit: 0% visibility for the customer's brand in English-language AI search. Competitors (Competitor A 29%, Competitor B 34%, Competitor C 24%) are already AI-recommended
The CEO's ask boils down to three questions:
- Is my brand mentioned by AI at all? Mention rate across engines and time windows
- Which sites does AI cite when answering category questions? Those sites are the "munitions stockpile" I need to seed content into
- What are my competitors' AI assets, exactly? When AI mentions a specific competitor, which URLs back that mention — letting me reverse-engineer their GEO content placement
The first question is easy — run probes, look at mention rate; every commercial GEO tool does this. The second is medium difficulty — a Top Domains report aggregated by domain; most mainstream tools also handle this. The third is the critical one: commercial tools mostly stop at "list the total URLs cited for this competitor," but can't precisely say "in the AI sentence that mentions this competitor, which URL is the source backing it." That's the real reverse attribution.
I surveyed the existing tools
Before writing any code I signed up for trials of all the major English-language GEO monitoring SaaS. Rough taxonomy:
| Tool | Pricing | AI engine coverage | Differentiator | What's missing |
|---|---|---|---|---|
| Topify | $99-199/mo | 7+, the only one covering Doubao/DeepSeek/Qwen | Broadest Chinese-ecosystem coverage + Source Analysis | Basic plan's 100-prompt cap is tight for agencies |
| Profound | $499+/mo (quote-based) | 10+ (no Doubao) | Enterprise polish + HubSpot/Salesforce integrations | Expensive; weak Chinese-engine coverage |
| Peec.ai | €80-120/mo + add-ons | 5 (DeepSeek is an €80 add-on) | Lean European pricing | Narrowest engine coverage |
| Otterly | ~$50/mo | 5 | Friendly to small brands / freelancers | Shallow data depth |
| AthenaHQ | Enterprise quote | 5+ | Multi-client management for agencies | Low transparency + no Chinese |
What they all share: all SaaS, none disclose their data-processing details, none do span attribution, and none let you build custom AI engine adapters. Differentiation lives mostly in workflow polish + integration breadth + AI engine coverage count. The underlying data isn't a moat — the same probe prompt hitting the same OpenAI Responses API returns the same citations. What commercial SaaS sells is the "save two days of self-hosting work" delta.
The entire category is selling a $20/month service for $200/month. Objectively, for small-to-mid brands without engineering capacity, the markup is reasonable. But for teams with engineering capacity + a desire to customize + a stake in data sovereignty, there's a huge arbitrage gap.
Three reasons I built my own
1. Data sovereignty: probe prompts are themselves commercial strategy
A customer's probe prompts look like generic industry questions on the surface, but a carefully designed prompt set (which categories, which competitor names, which use-case scenarios) actually exposes their go-to-market thinking. Putting that into a third-party SaaS database = your strategy is transparent to the vendor. For someone like X, mid-flight on a GEO breakout plan, uploading the prompt set to a US SaaS vendor (however reputable) is an internal compliance event requiring sign-off. Self-hosted SQLite eliminates that friction entirely.
2. Differentiation: I wanted to ship span attribution
This is the real differentiating feature. Commercial tools, at best, tell you:
"Last week, Reddit was cited in 78% of AI answers for your category."
What I want is one more sentence:
"Reddit was cited 78%. Of that, 23% precisely backs the sentence that mentions your brand — versus 55% that backs unrelated competitor mentions or generic industry commentary."
The data-driven actions for those two versions are completely different. Version one only lets you say "Reddit is a high-frequency citation source" — useless, every competitor knows that. Version two lets you distinguish "Reddit is a generic citation source in my category" vs. "Reddit is a real endorsement source for my brand" vs. "Reddit cites everyone in my category except me." That last case signals a real content gap (gap analysis).
3. China AI engine coverage: Doubao / Kimi / DeepSeek
If the customer only does Europe/US export, international AI engines are enough. But X also wants to cover domestic inquiry scenarios (some large Chinese buyers ask Doubao for supplier recommendations), and at the next stage I plan to expand GEO services to domestic brands. That means Doubao / Kimi / DeepSeek must be supportable. Topify is the only commercial tool covering international + Chinese engines together, and I talked to them about a trial, but their Doubao path runs cookie reverse-engineering with high account-token failure rates. I wanted the official API route — and Volcengine Ark's Responses API + built-in web_search tool, launched in Q1 2026, fits perfectly.
What CiteScope is
The UI looks like this — the overview page shows 7-day mention rates across all customers:
Each monitored target has its own "probe question bank," importable via CSV, with questions tagged by category / competitor / use-case:
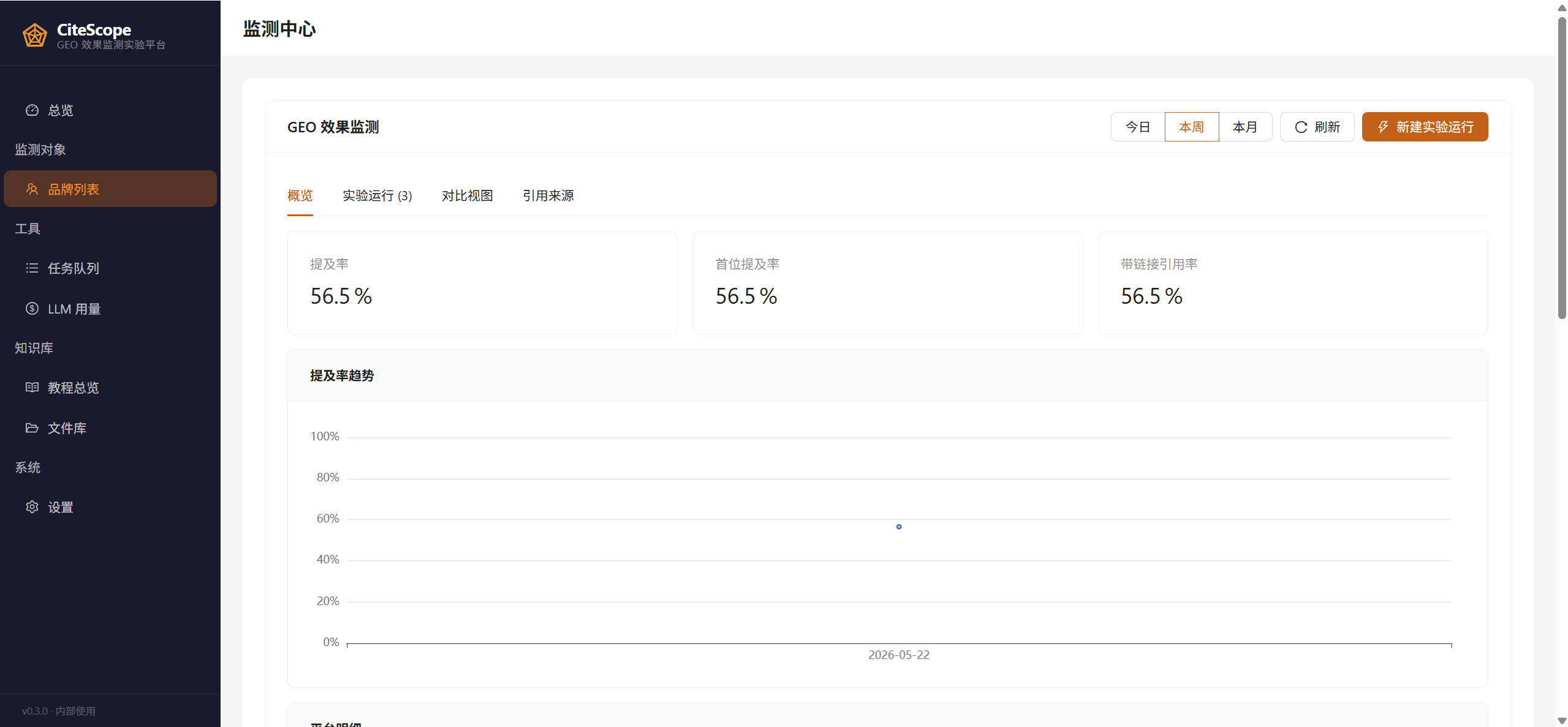
The core unit of work is a Run — one Run = one set of probes × multiple AI engines × one timestamp. The monitoring center's "Overview" tab gives you the customer's KPI dashboard:
Architecture, 30-second version:
React + Vite + Antd 5
│ HTTP/REST
▼
FastAPI + uvicorn + SQLAlchemy + APScheduler
│
├──→ AI adapters ×6 (ChatGPT/Perplexity/Gemini/Doubao/Kimi/DeepSeek)
├──→ SQLite (WAL mode)
└──→ background citation resolver job (one Gemini wrapper batch every 5 min)
Single process + single DB file, no Redis / Celery / Postgres required to start. 1 vCPU / 1 GB RAM is enough. One line — docker compose up -d — and you're running, open localhost:3000.
The core differentiator: what span attribution is
This is the biggest single difference between CiteScope and the commercial tools. Worth a section to itself.
AI answers usually carry [citation:N] markers (or OpenAI's url_citation annotations, Gemini's groundingMetadata, Volcengine Ark's annotations). Each citation has a start_index and end_index, pointing to the span of text in the AI answer it's meant to support.
Commercial tools use only half of this information when they ingest citations: URL + title. They throw away the span info. So the best they can tell you is "this domain was cited N times."
CiteScope does one extra step: it computes both the positions of [citation:N] markers and the positions of brand keywords, splits the AI answer into sentences, and checks whether a citation falls in the same sentence as a brand mention. If yes, that citation actually backs your brand; if not, it's just generic citation.
The algorithm is 90 lines of Python (backend/app/services/citation_analysis/span_attribution.py). Core logic:
def compute_supports_brand_mention(
raw_answer: str,
brand_keywords: list[str],
cite_indices: list[int],
) -> dict[int, bool]:
# 1) find all char-spans where brand keywords appear (case-insensitive)
brand_spans = find_keyword_spans(raw_answer, brand_keywords)
# 2) find all [citation:N] marker positions, grouped by N
markers_by_n = find_citation_markers(raw_answer)
# 3) sentence-split (mixed Chinese/English punctuation),
# for each sentence: if it contains both a brand_span and a marker → that N = True
supported = set()
for s, e, _ in iter_sentence_spans(raw_answer):
has_brand = any(span_overlaps(bs, be, s, e) for bs, be in brand_spans)
if not has_brand:
continue
for n, ms in markers_by_n.items():
if any(span_overlaps(ms_s, ms_e, s, e) for ms_s, ms_e in ms):
supported.add(n)
return {n: (n in supported) for n in cite_indices}
The hard part isn't the algorithm, it's three details: (1) sentence segmentation for mixed Chinese/English text (Chinese full-stops typically have no trailing space, and English periods butted up against Chinese characters also need to split); (2) normalizing the citation marker formats returned by each AI engine; (3) reinserting markers into the original body text (OpenAI / Ark return span indices, so you need to insert [citation:N] back in reverse end_index order so downstream code can run).
I stepped on each of these once. OpenAI's chat completions + search-preview doesn't return spans (only an annotations array), so the ChatGPT adapter is currently stuck doing "answer-level" attribution only; Gemini's grounding_supports has segment.start_index/end_index that needs manual reassembly; Ark's url_citation aligns closely with OpenAI Responses but its token-accounting field names are input_tokens/output_tokens. The full alignment work took two weeks.
Why don't commercial tools do this? My guess: two reasons. (1) Compute cost isn't trivial and the marketing pitch isn't obvious — "Reddit cited 78%" looks more striking than "Reddit backs your brand 30%"; (2) once you ship it, you expose how shallow most "citation tracking" actually is. It's a committing-to-ship problem, not an algorithm problem.
Real data: Top Domains pulled from customer X
Customer X ran three Runs (baseline → after editing llms.txt → after adding FAQ schema), across 3 weeks, ~700 citations. The Top Domains report — the "AI munitions stockpile" — came back as:
| Domain | Citations | Cross-platform | Reading |
|---|---|---|---|
made-in-china.com | 40 | 3 platforms | B2B sourcing top tier, AI treats it as authoritative |
alibaba.com | 32 | 2 platforms | Same tier, slightly lower ChatGPT preference |
competitor-a.com | 31 | 2 platforms | Competitor A's own site — strong SEO signal |
competitor-b.com | 20 | 3 platforms | Competitor B's own site |
competitor-c.com | 19 | 3 platforms | Competitor C's own site |
industry-listicle-a.com | 19 | 3 platforms | Industry "top 10" listicle article |
jingsourcing.com | 12 | 3 platforms | Sourcing-agent blog |
industry-listicle-b.com | 11 | 1 platform (Gemini) | "Hidden" authority surfaced by Gemini |
This list translates directly into three content placement actions:
- marketplace listing optimization: round out the customer's listing on made-in-china.com / alibaba.com (certifications, product specs, video) — top-tier authorities
- cluster journalism inclusion: for "top 10 industry supplier" blogs like industry-listicle-a.com / industry-listicle-b.com, find author emails and pitch them to add the customer (with certifications + case studies)
- competitor reverse engineering: study competitor-a.com / competitor-b.com / competitor-c.com — their page schema, FAQ blocks, customer case write-ups — and benchmark the gap
More importantly, the Run comparison view lets you validate the causal effect of GEO interventions. The figure below shows X's three-Run comparison — the matrix shows mention rate climbing from baseline 0% → 30.4% after editing llms.txt → 56.5% after adding FAQ schema, and the radar chart shows the per-platform preference differences simultaneously:
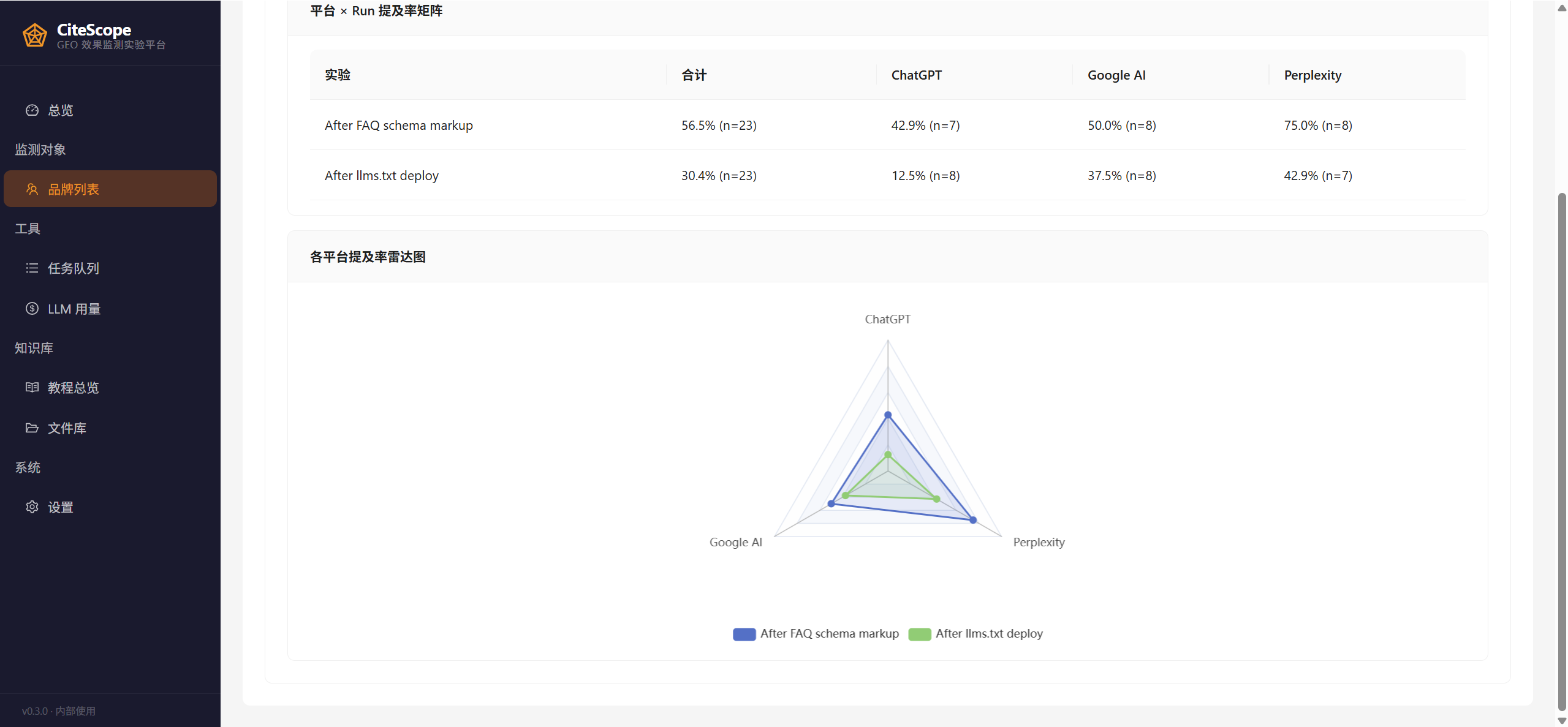
Without Run comparison you can't do this kind of causal attribution. CiteScope treats each monitoring pass as a versioned Run (with a name + note), and cross-Run comparison is the essential difference from Topify's "run automatically once a week and draw a line chart" — the latter only shows trends, the former lets you test hypotheses.
How to run it yourself
One command:
git clone https://github.com/piglet12138/CiteScope.git cd CiteScope cp backend/.env.example backend/.env # open backend/.env and fill in three keys: # OPENAI_OFFICIAL_API_KEY=sk-... # PERPLEXITY_API_KEY=... # GOOGLE_AI_API_KEY=... docker compose up -d # open http://localhost:3000 in your browser
The key-entry page looks like this — it lands you on the "AI Search / Monitoring Platforms" tab by default, with one card per platform, plus a sign-up link and a test-connection button:
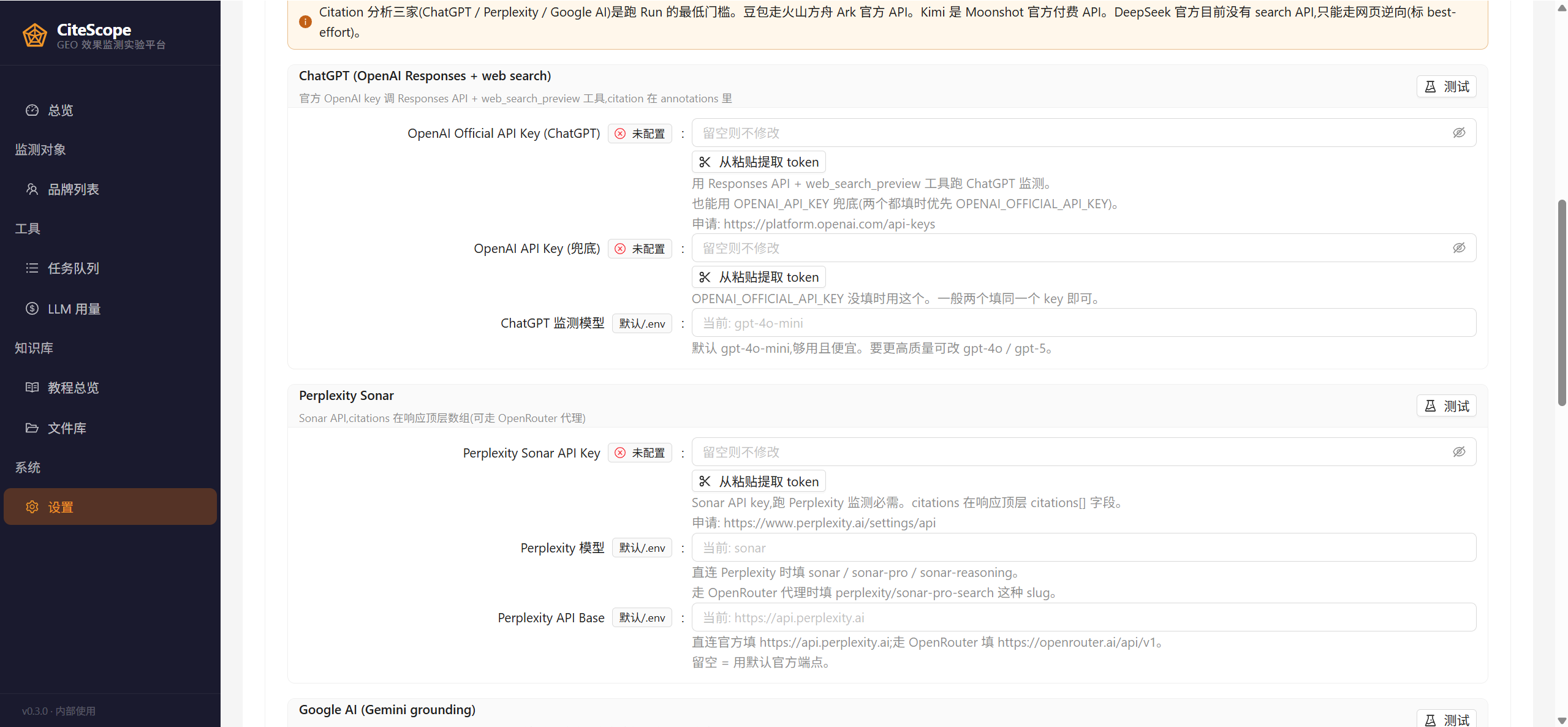
API key signup:
- OpenAI Official: platform.openai.com/api-keys (for ChatGPT web search)
- Perplexity Sonar: perplexity.ai/settings/api (or via OpenRouter — set PERPLEXITY_API_BASE to
https://openrouter.ai/api/v1) - Google AI Studio: aistudio.google.com/apikey
- Optional Volcengine Ark: volcengine.com/product/ark (Doubao)
Budget estimate: 100 prompts × 3 platforms × once a week — a typical cadence — comes out to $5-15/month in API spend. Topify charges $99/month for the same data.
After setup, hit localhost:3000 → Brands → New Customer → enter probe questions → Monitoring Center → New Experiment Run. Five minutes later you have Top Domains + Competitor Assets reports under the Citation Sources tab.
The full user manual is embedded in-app — no shoving users out to a GitHub wiki, just hit the /guides route. 8 standalone module guides, markdown-rendered:
Why open source instead of selling SaaS
This is the question I asked myself most over the past two weeks. Packaging this real customer case + the differentiating feature + the already-built product into a $49/mo SaaS is theoretically viable. I still chose open source. Three reasons.
1. A solo dev doesn't have a 12-month full-time runway
I'm running the customer's GEO work, Lucky GitHub agent, claude-ai-harness, the claude-zh CC fork, and several other projects in parallel. Commercializing CiteScope means 6-12 months of full-time GTM (landing page / SEO / content marketing / customer support / international payment compliance) going head-to-head with VC-backed Topify / Profound. Solo + China-based entity + selling international B2B SaaS — the odds are too thin.
2. Open Core is already a validated playbook
PostHog (analytics) / Plausible / Cal.com / Supabase / n8n are all OSS core + later-layered hosted SaaS, starting with 1-2 people, hitting $100K+ ARR within 2-3 years. The pattern is identical:
- First 6 months: focus on open source — accumulate stars / community feedback / early power users
- Watch for the recurring "I'd use this but can't self-host" signal
- Then launch the hosted version, sold to that segment (selling hosting + multi-tenant + priority support, not the core feature)
This path is the most capital-efficient — near-zero marginal cost in the first 6 months, with time investment concentrated on maintenance + issue triage + blog posts (5-10 hours/week), parallelizable with my other projects.
3. Customer cases can only be cited under open source
SaaS contracts forbid surfacing a customer's probe prompts / citations as a public case study (violates the customer contract). Open source can: because the customer self-hosts, all data lives in their own SQLite, and what I show is "data they ran with my OSS," not "data I pulled out for them." That kind of case study is more credible than any number of product screenshots.
Roadmap
The concrete 6-month path:
- Week 1-2 (now): post + submit to Show HN / Reddit / Jike / Zhihu, collect the first batch of stars
- Month 1: collect signals — GitHub stars / issues / who forks, watch for anyone opening "feat: hosted version please" issues
- Month 2-3: ship v0.2 features (Postgres / more AI adapters / Slack alerting)
- Month 4: decision point — if 500+ stars + 5+ unsolicited inquiries about hosted, launch hosted version (
citescope.cloud) - Month 5-6 (if hosted launches): multi-tenant + Stripe + pricing at $19/49/199 per month (all below Topify's $99 starting tier). Customer case studies on the homepage
The inverse — when to skip open source and go straight to SaaS: 12 months of full-time runway / 5+ customers already lined up / a EU/US legal entity for clean payment processing. None of those hold for me, so the path is set.
Feedback I'm hoping to get
- Bug reports, any flavor — adapter output not matching the vendor's real response, span attribution mishandling some Unicode edge case, operations issues
- New adapter contributions, for engines I don't yet cover — Bing Copilot / Claude.ai / You.com / Brave Search are all on the wishlist. The adapter template is simple — copy
chatgpt.py, change 60 lines, and you've got a new engine - Use-case stories — what would you do with this data that commercial tools don't let you do? Tell me, and I'll prioritize features that unlock those workflows
GitHub Issues / Discussions are open. English or Chinese, both work.
One last thing
GEO becomes table stakes by 2027. Every brand that cares about discoverability will measure it. The question is how — a $99/mo Topify dashboard, or your own $0/mo SQLite file plus the freedom to fork and extend.
I'm betting on the second world. If you're betting the same way, give us a star, run a Run, and tell me what's missing.
https://sg.yaoyuheng2001.me/posts/open-source-citescope/en.
For commercial use, please contact the author via the blog for authorization.